 |
University of Jyväskylä
Department of Mathematical Information Technology
LAMDA - Computationally Intelligent Analysis of Qualitative Data
Prof. Pasi Koikkalainen (project leader) and MSc(eng) Anssi Lensu
|
In LAMDA we work in collaboration with the
Institute for Educational Research as part of their CATO
project group. Our goal is to develop an analysis framework of quantitative
methods that can be used to analyze the data obtained using questionnaires.
The answers to the questionnaires usually contain numerical, multi-choice
and free-form textual data.
All data types can be analyzed using
Self-Organizing
Maps.
However, the data sets need to be preprocessed properly first, and
in most cases several SOMs need to be trained.
Numerical and Multi-choice Data
For numerical data equalization of the ranges of variable values
according to their minimums
and maximums is usually enough, and then a SOM can be trained.
For Multi-choice data we could
use n X c dummy variables, where n is the number
of multi-choice questions and c is the number of choices.
However, this kind of preprocessing results in a SOM, from which it is
very difficult to obtain meaningful results, because the SOM is not
ordered. This is due to the fact that there is no connection between
the variables representing the different choices of a single question.
Also, the number of variables can be quite large compared to
the number of available data records, m.
To attack the presented problems we have proposed a multi-stage system
in which the data is first preprocessed using fuzzy coding that provides
a connection between the different choices of the same question.
The number of variables can be kept rather small be dividing the original
questions into a few categories and later combining the results using
fuzzy group memberships.
These group memberships indicate with a truth value whether a certain
data record (or answer form) should belong to a group of data records
which represent a certain opinion or not.
The details of this approach are presented in the proceedings of
ICANN'98 and
STeP'98, and there is
a brief overview in Figure 1.
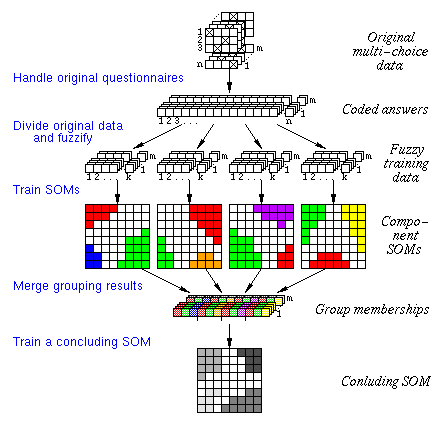
Figure 1. Our approach to the analysis of multi-choice data.
Textual Data
Currently, we are building a system that should be able to locate similar
documents from a huge collection of texts. The system we have built is able
to group similar words, sentences and documents together, and the resulting
model can be used for
queries and for providing descriptions to the original documents.
The size (number of neurons) of each SOM can be chosen by calculating
the model complexity of each layer of the
TS-SOM
and by choosing the
simplest model that is still able to represent the original data properly.
The model is built in two or three phases:
- All words, wi, in the original documents,
dk, are preprocessed and grouped using
a SOM, Sw.
- Description vectors, vj, for the sentences,
sj, are formed by using Sw.
vj indicates, what kind of words are present,
and in which order, in sentence j.
A new SOM, Ss, is trained using these vectors.
- Description vectors, uk, for the documents,
dk, are formed by using Ss.
uk indicates, what kind of sentences are present
in document k.
A new SOM, Sd, is trained using these vectors.
The third phase is optional, because Sw and
Ss can already be used for word or sentence based
queries, and Ss is usually enough for specifying
descriptions for the original documents.
These descriptions usually indicate that a certain group of documents
contains a certain opinion or idea. They can be used in conjunction
with the fuzzy group memberships obtained from the multi-choice analysis
to form a concluding model of the whole data set.
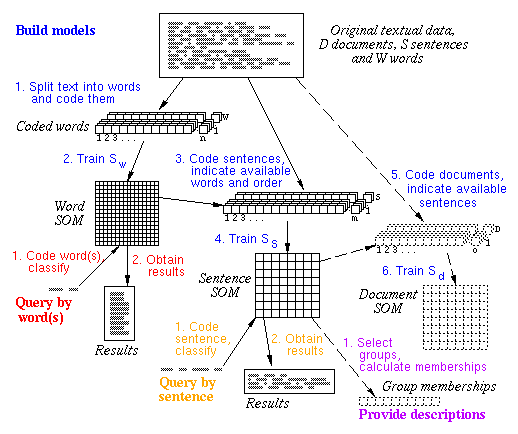
| Figure 2. |
Our approach to the building of a SOM model for textual data.
Picture also describes how the model can be used for queries and
for providing descriptions to original documents.
|
Publications
Here is a presentation
given by Anssi Lensu to the coordinator of the Academy of Finland on
August 7th, 1998.
The text analysis part has changed a lot after this
presentation.
 This page was last modified on May 31st, 2000 by Anssi Lensu
This page was last modified on May 31st, 2000 by Anssi Lensu